

The Llama 3.1 model family includes the following sizes:
- 8B
- 70B
- 405B
Llama 3.1 405B stands out as the first open-access model that matches the top-tier AI models in areas like general knowledge, adaptability, mathematics, tool utilization, and multilingual translation.
The upgraded 8B and 70B models are multilingual, feature an extended context length of 128K, and offer advanced tool integration and stronger reasoning abilities. These improvements enable Meta’s latest models to excel in use cases like long-form text summarization, multilingual conversational agents, and coding assistants.
Meta has also updated its licensing terms, allowing developers to leverage Llama model outputs, including those from the 405B model, to enhance other models.
Model Evaluations
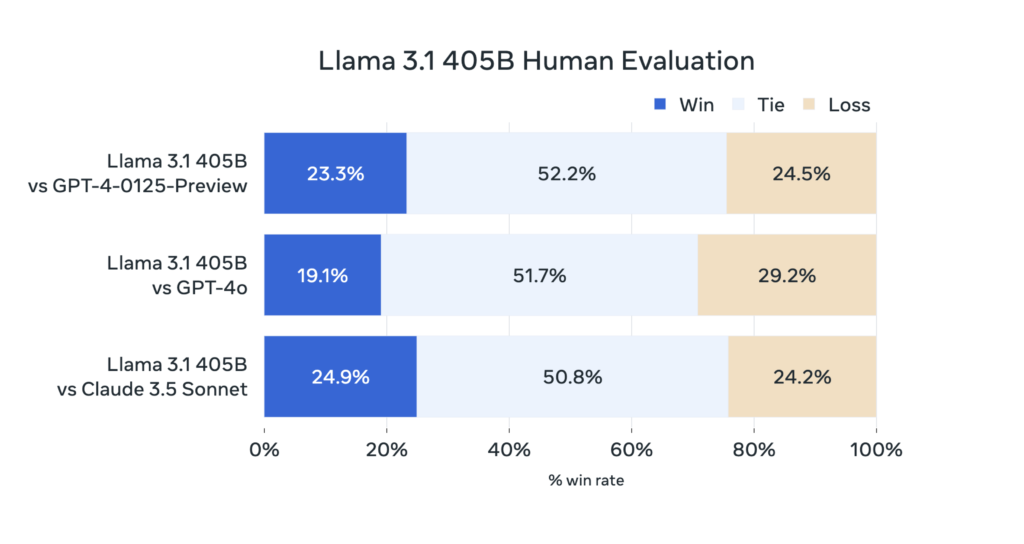
Meta evaluated Llama 3.1’s performance on more than 150 benchmark datasets covering a wide range of languages. Extensive human evaluations were also conducted, comparing Llama 3.1 to competing models in real-world scenarios. Results show that the flagship 405B model is competitive with top foundation models, including GPT-4, GPT-4o, and Claude 3.5 Sonnet, across various tasks.
Additionally, Meta’s smaller models hold their own against both open and closed models with a comparable number of parameters.
| Category | Benchmark | Llama 3.1 8B | Llama 3 8B – April | Llama 3.1 70B | Llama 3 70B – April | Llama 3.1 405B |
|---|---|---|---|---|---|---|
| General | MMLU | 73.0 | 65.3 | 86.0 | 80.9 | 88.6 |
| MMLU PRO (5-shot, CoT) | 48.3 | 45.5 | 66.4 | 63.4 | 73.3 | |
| IFEval | 80.4 | 76.8 | 87.5 | 82.9 | 88.6 | |
| Code | HumanEval (0-shot) | 72.6 | 60.4 | 80.5 | 81.7 | 89.0 |
| MBPP EvalPlus (base, 0-shot) | 72.8 | 70.6 | 86.0 | 82.5 | 88.6 | |
| Math | GSM8K (8-shot, CoT) | 84.5 | 80.6 | 95.1 | 93.0 | 96.8 |
| MATH (0-shot, CoT) | 51.9 | 29.1 | 68.0 | 51.0 | 73.8 | |
| Reasoning | ARC Challenge (0-shot) | 83.4 | 82.4 | 94.8 | 94.4 | 96.9 |
| GPQA (0-shot, CoT) | 32.8 | 34.6 | 46.7 | 39.5 | 51.1 | |
| Tool Use | API-Bank (0-shot) | 82.6 | 48.3 | 90.0 | 85.1 | 92.3 |
| BFCL | 76.1 | 60.3 | 84.8 | 83.0 | 88.5 | |
| Gorilla Benchmark API Bench | 8.2 | 1.7 | 29.7 | 14.7 | 35.3 | |
| Nexus (0-shot) | 38.5 | 18.1 | 56.7 | 47.8 | 58.7 | |
| Multilingual | Multilingual MGSM | 68.9 | – | 86.9 | – | 91.6 |
This table summarizes the performance of the Llama 3.1 and Llama 3 models across various benchmarks and tasks.
How to run Llama 3.1 using Ollama
Llama 3.1 is a new state-of-the-art model from Meta available in 8B, 70B and 405B parameter sizes. Run Llama 3.1 using Ollama:
ollama run llama3.1