

Mistral is a 7B parameter model, distributed with the Apache license. It is available in both instruct (instruction following) and text completion.
The Mistral AI team has noted that Mistral 7B:
- Outperforms Llama 2 13B on all benchmarks
- Outperforms Llama 1 34B on many benchmarks
- Approaches CodeLlama 7B performance on code, while remaining good at English tasks
Performance in details
We compared Mistral 7B to the Llama 2 family, and re-run all model evaluations ourselves for fair comparison.
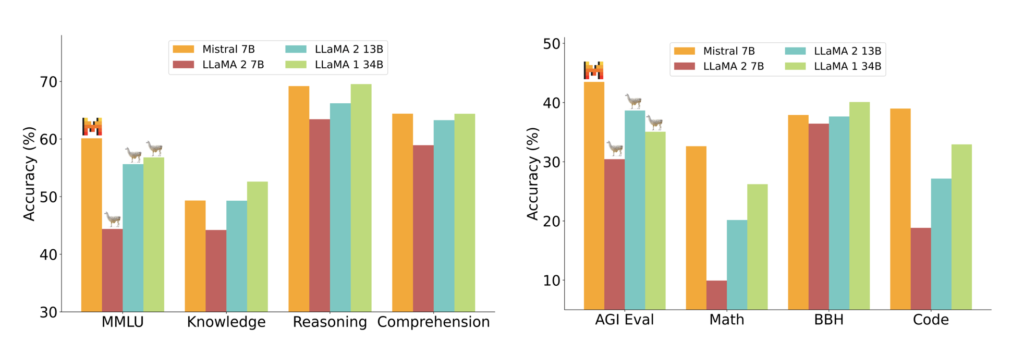
The performance comparison between Mistral 7B and various Llama models was evaluated across multiple benchmarks using a standardized evaluation pipeline for accurate results. Mistral 7B significantly outperformed Llama 2 13B on all metrics and performed on par with the Llama 34B model (since Llama 2 34B was not released, the Llama 34B results were used). Additionally, Mistral 7B demonstrated superior performance in coding and reasoning tasks.
The benchmarks were grouped based on the following themes:
- Commonsense Reasoning: 0-shot average from Hellaswag, Winogrande, PIQA, SIQA, OpenbookQA, ARC-Easy, ARC-Challenge, and CommonsenseQA.
- World Knowledge: 5-shot average from NaturalQuestions and TriviaQA.
- Reading Comprehension: 0-shot average from BoolQ and QuAC.
- Math: Averaged results from 8-shot GSM8K (maj@8) and 4-shot MATH (maj@4).
- Code: Averaged results from 0-shot Humaneval and 3-shot MBPP.
- Aggregated Popular Results: 5-shot MMLU, 3-shot BBH, and 3-5-shot AGI Eval (English multiple-choice questions).
Run Mistral
ollama run mistral