

Phi-4 is a 14B parameter, state-of-the-art open model built upon a blend of synthetic datasets, data from filtered public domain websites, and acquired academic books and Q&A datasets. The model was extensively refined and aligned through a combination of supervised fine-tuning and direct preference optimization, ensuring accurate instruction adherence and strong safety protocols.
ollama run phi4Context length: 16k tokens.

Primary Use Cases
The model is intended to advance research on language models and serve as a foundational component for generative AI-powered features. It is suitable for general-purpose AI systems and applications (primarily in English) that require:
- Memory/compute-constrained environments: Optimized for scenarios where resources are limited.
- Latency-bound scenarios: Designed for applications where response speed is critical.
- Reasoning and logic: Effective for tasks involving problem-solving or complex thought processes.
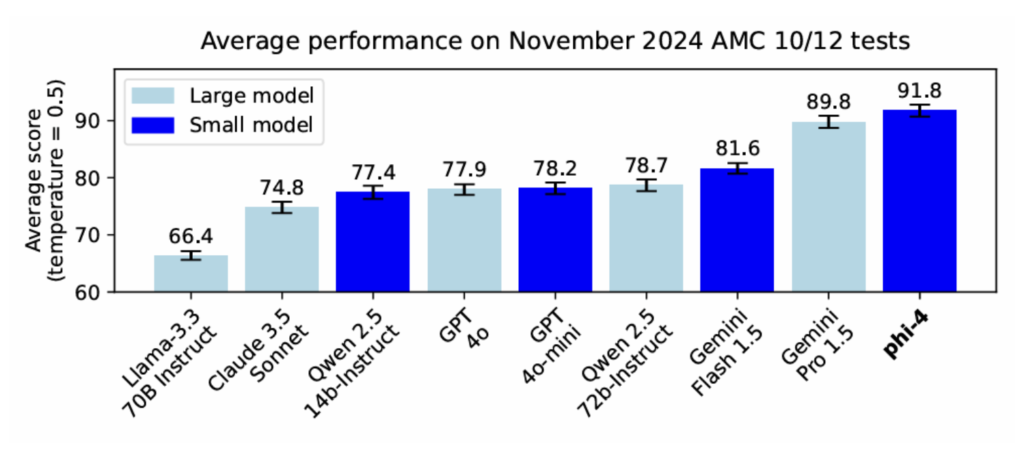
Out-of-Scope Use Cases
The model is not specifically designed or evaluated for all possible downstream applications. Therefore:
- Evaluation and mitigation: Developers should account for common limitations of language models and thoroughly assess and address accuracy, safety, and fairness concerns before deployment, especially in high-risk contexts.
- Regulatory compliance: Developers must comply with applicable laws and regulations (e.g., privacy, trade compliance) relevant to their use case, considering the model’s primary focus on English.
- License adherence: This readme does not impose any restrictions or modifications to the terms of the license under which the model is released.